







Presentation Summary
Explore the intricacies of big data and cloud computing architecture, including the three Vs of big data, cloud platform comparisons, and storage strategies.
Full Presentation Transcript
Slide 1: Big Data and Cloud Computing Architecture
System Overview: Volume, Velocity, Variety, Cloud Platforms Comparison, and Storage Architecture Strategies
Slide 2: Contents
- Big Data Fundamentals: Understanding Volume, Velocity, and Variety: the three defining characteristics of modern Big Data systems.
- Cloud Platform Ecosystem: AWS, Azure, GCP comparison: services, capabilities, and selection criteria for big data architecture.
- Storage Architecture Strategy: Data Lakes vs Data Warehouses: technical analysis, use cases, and implementation guidance.
Slide 3: The Big Data Challenge: Modern Architecture Paradigms
- Data Explosion Scale: 2.5 quintillion bytes generated daily. 40 zettabytes projected by 2026, representing 300x growth since 2005.
- Enterprise Pain Points: Legacy systems fail at petabyte-scale unstructured data. Real-time processing requirements exceed traditional capabilities. Diverse data formats demand flexible architectures.
- Business Imperative: Transform data volume from operational burden into strategic asset. Cloud-native architecture enables scalability, real-time insights, and cost optimization.
Slide 4: Volume: Unprecedented Scale Requires Cloud-Native Architecture
- Technical Foundation: Object storage over block storage. Distributed file systems including HDFS, S3, Azure Blob. Compute-storage decoupling for independent scaling.
- Real-World Scale: Enterprise data warehouses reaching 100+ TB. IoT platforms ingesting petabytes monthly. Social media platforms storing exabytes.
- Cost Optimization: Cloud tiered storage: hot, warm, cold data classification. TCO reduction of 60-80% vs on-premises. Pay-as-you-grow pricing models.
- Scalability Pattern: Horizontal scaling through distributed nodes. Auto-scaling based on workload demands. Global replication for disaster recovery.
Data volume represents the sheer amount of data organizations must store and process, ranging from terabytes to petabytes, requiring horizontally scalable infrastructure.
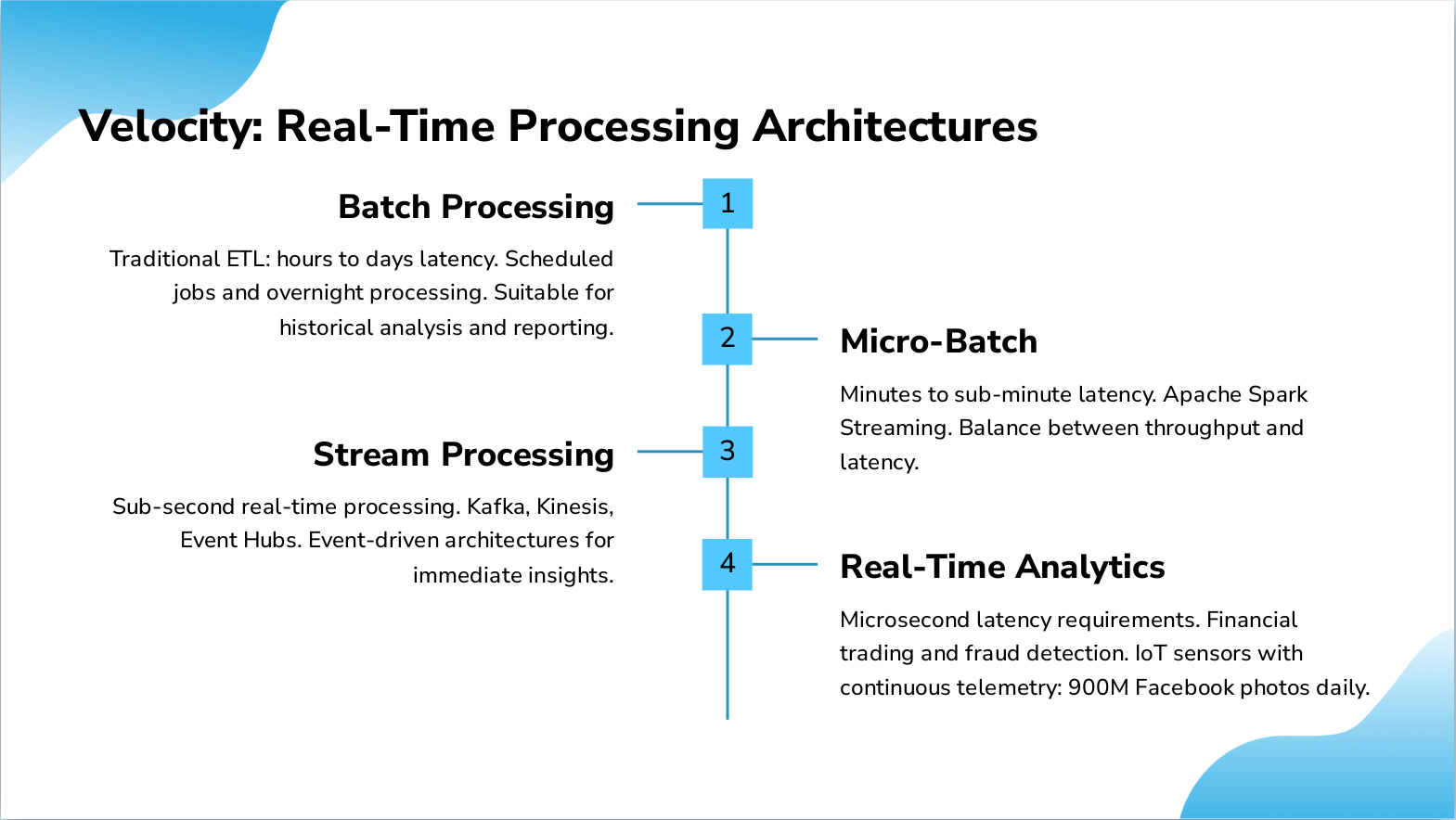
Slide 5: Velocity: Real-Time Processing Architectures
- Batch Processing: Traditional ETL: hours to days latency. Scheduled jobs and overnight processing. Suitable for historical analysis and reporting.
- Micro-Batch: Minutes to sub-minute latency. Apache Spark Streaming. Balance between throughput and latency.
- Stream Processing: Sub-second real-time processing. Kafka, Kinesis, Event Hubs. Event-driven architectures for immediate insights.
- Real-Time Analytics: Microsecond latency requirements. Financial trading and fraud detection. IoT sensors with continuous telemetry: 900M Facebook photos daily.
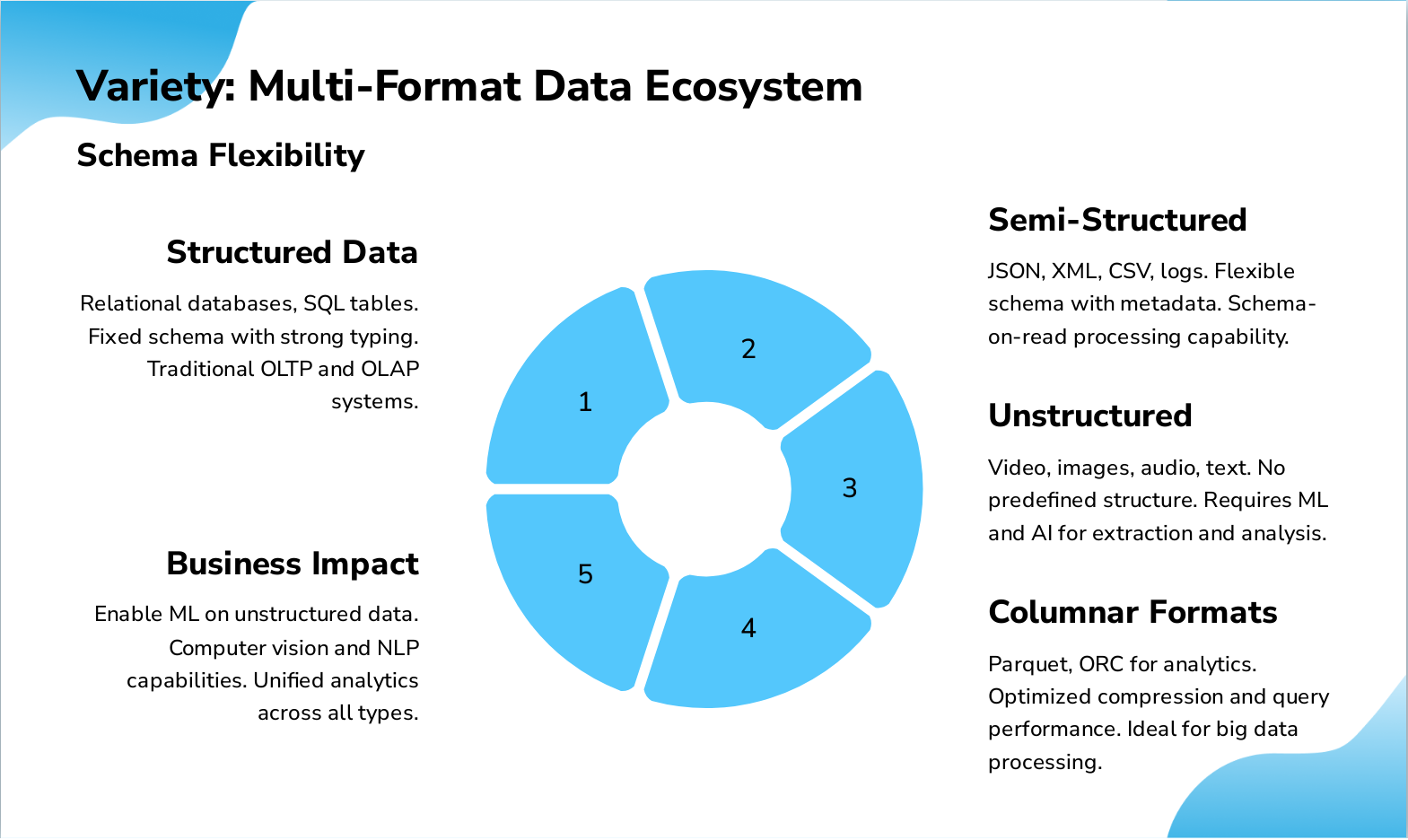
Slide 6: Variety: Multi-Format Data Ecosystem
- Structured Data: Relational databases, SQL tables. Fixed schema with strong typing. Traditional OLTP and OLAP systems.
- Semi-Structured: JSON, XML, CSV, logs. Flexible schema with metadata. Schema-on-read processing capability.
- Unstructured: Video, images, audio, text. No predefined structure. Requires ML and AI for extraction and analysis.
- Columnar Formats: Parquet, ORC for analytics. Optimized compression and query performance. Ideal for big data processing.
- Business Impact: Enable ML on unstructured data. Computer vision and NLP capabilities. Unified analytics across all types.
Slide 7: Cloud Platform Comparison: AWS, Azure, GCP
Market positioning, key differentiators, and strategic considerations
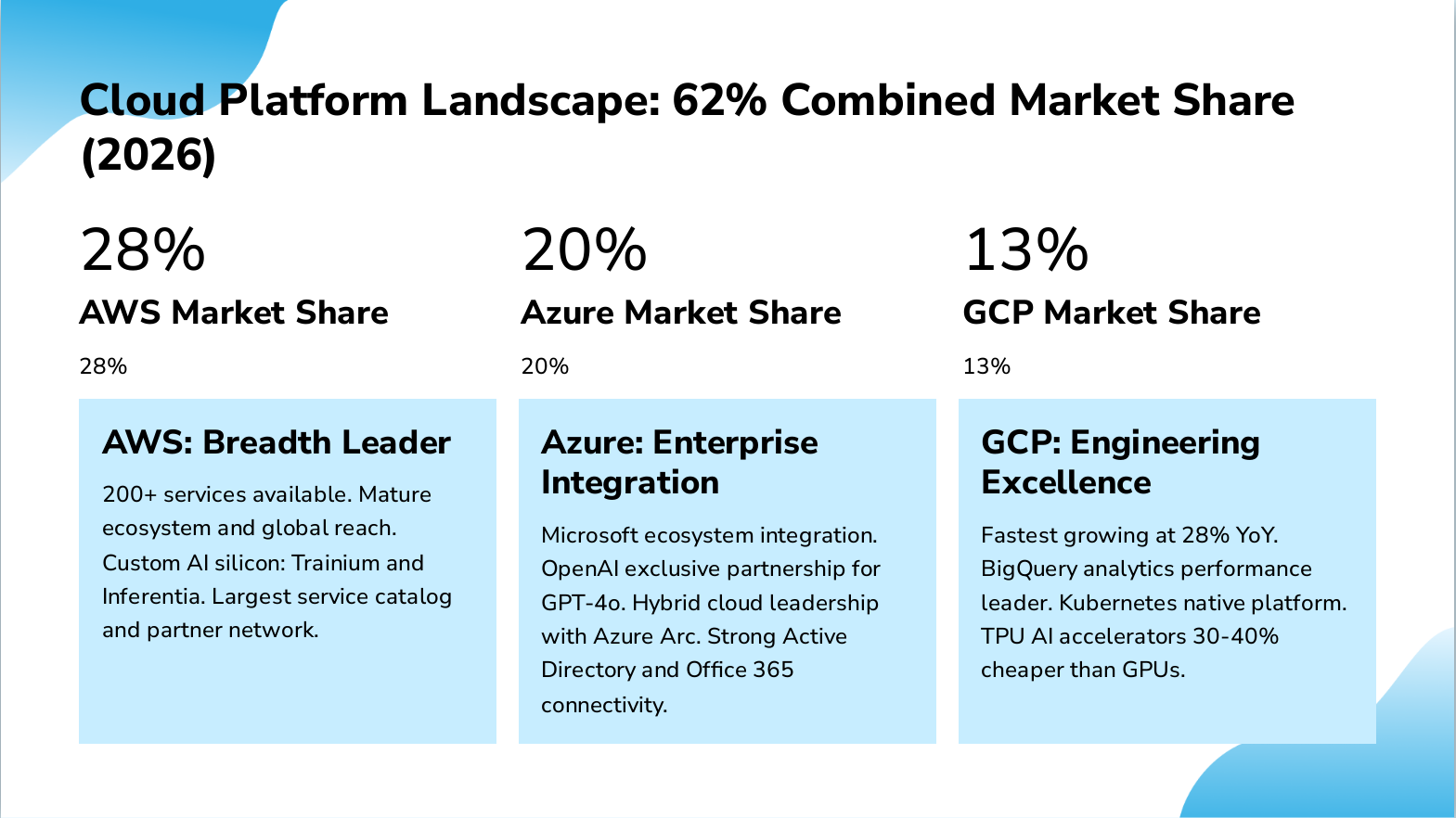
Slide 8: Cloud Platform Landscape: 62% Combined Market Share (2026)
- 28% — AWS Market Share
- 20% — Azure Market Share
- 13% — GCP Market Share
- AWS: Breadth Leader: 200+ services available. Mature ecosystem and global reach. Custom AI silicon: Trainium and Inferentia. Largest service catalog and partner network.
- Azure: Enterprise Integration: Microsoft ecosystem integration. OpenAI exclusive partnership for GPT-4o. Hybrid cloud leadership with Azure Arc. Strong Active Directory and Office 365 connectivity.
- GCP: Engineering Excellence: Fastest growing at 28% YoY. BigQuery analytics performance leader. Kubernetes native platform. TPU AI accelerators 30-40% cheaper than GPUs.
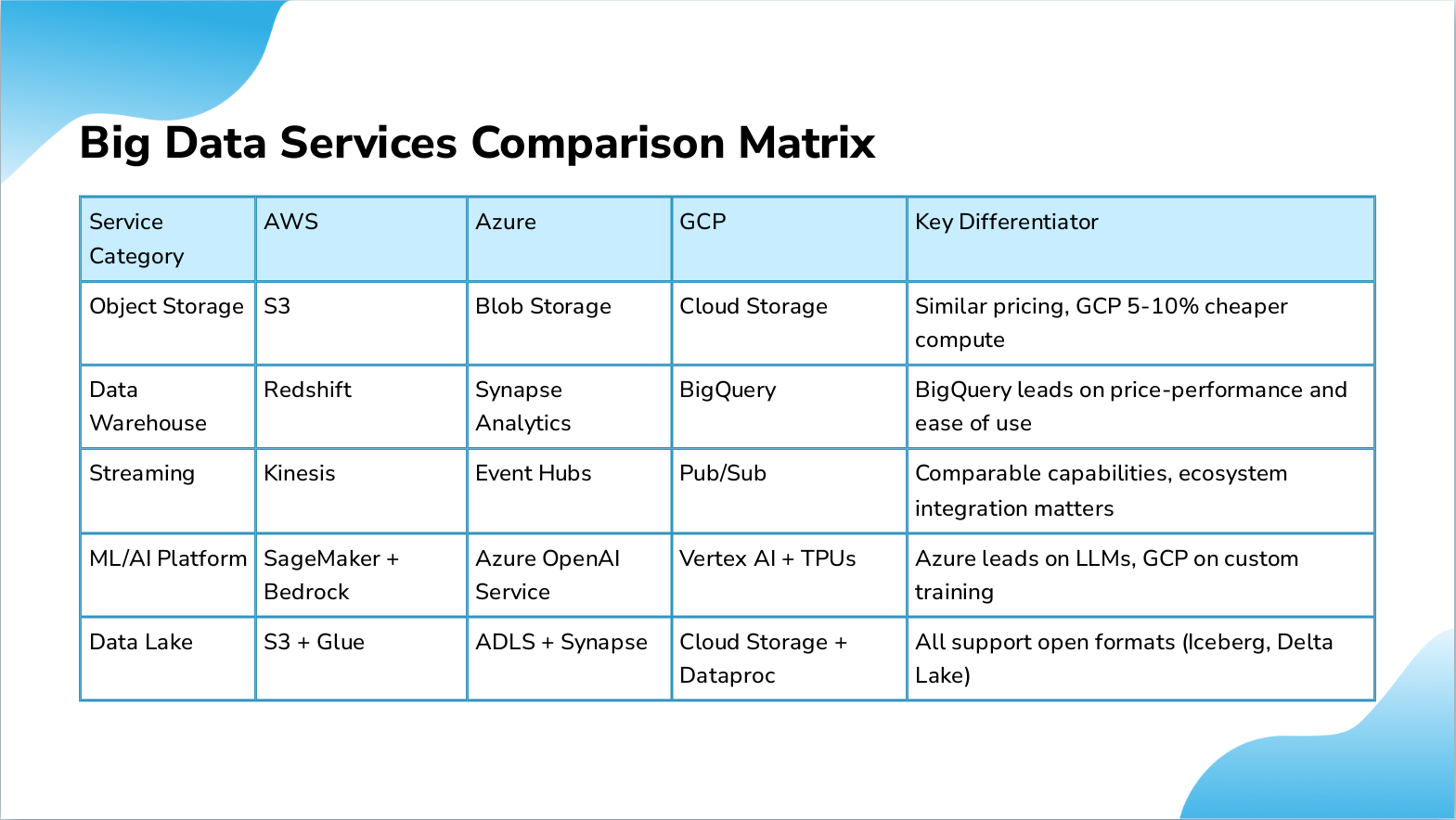
Slide 9: Big Data Services Comparison Matrix
- Service Category: Object Storage, AWS: S3, Azure: Blob Storage, GCP: Cloud Storage, Key Differentiator: Similar pricing, GCP 5-10% cheaper compute
- Service Category: Data Warehouse, AWS: Redshift, Azure: Synapse Analytics, GCP: BigQuery, Key Differentiator: BigQuery leads on price-performance and ease of use
- Service Category: Streaming, AWS: Kinesis, Azure: Event Hubs, GCP: Pub/Sub, Key Differentiator: Comparable capabilities, ecosystem integration matters
- Service Category: ML/AI Platform, AWS: SageMaker + Bedrock, Azure: Azure OpenAI Service, GCP: Vertex AI + TPUs, Key Differentiator: Azure leads on LLMs, GCP on custom training
- Service Category: Data Lake, AWS: S3 + Glue, Azure: ADLS + Synapse, GCP: Cloud Storage + Dataproc, Key Differentiator: All support open formats (Iceberg, Delta Lake)
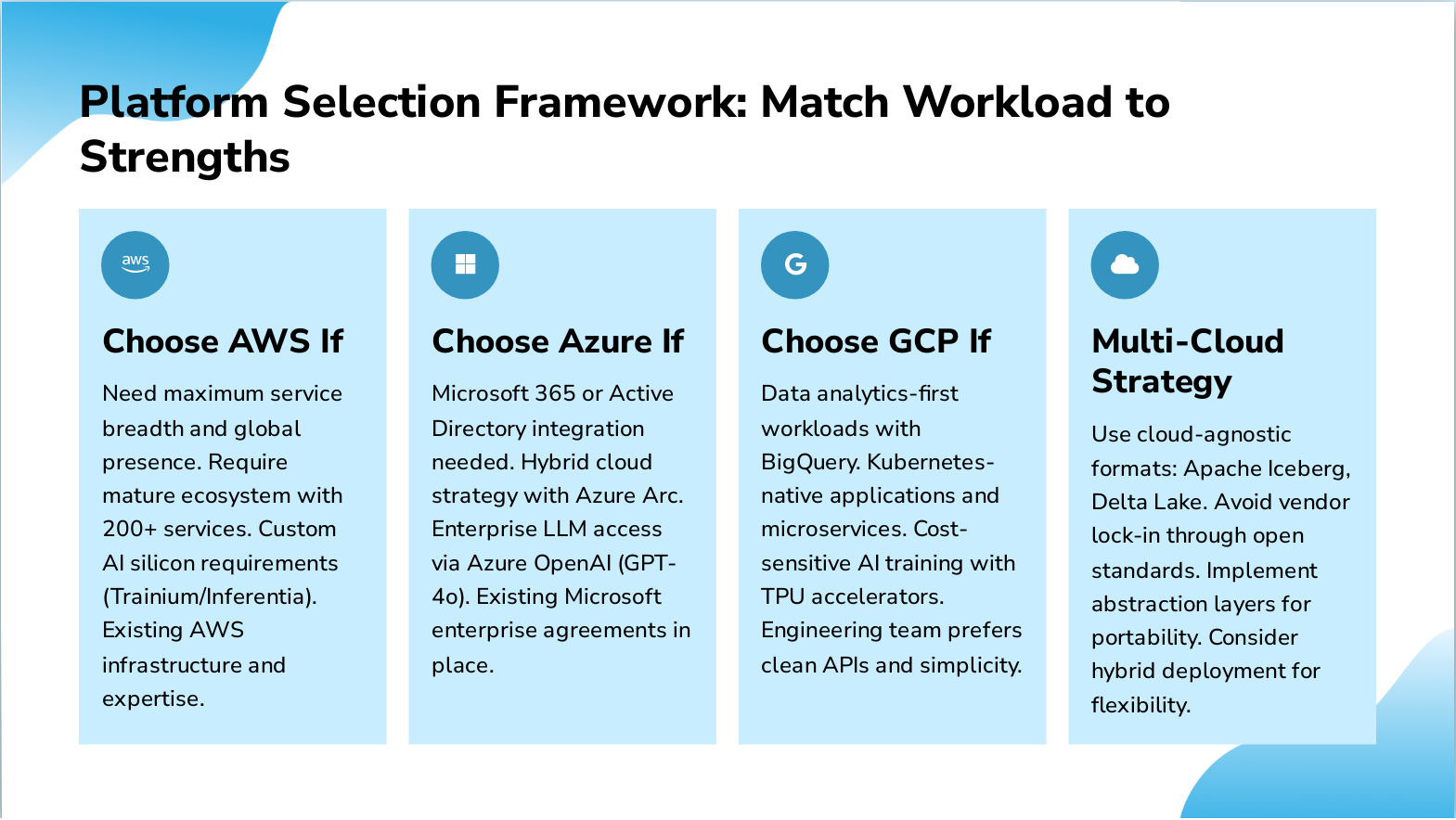
Slide 10: Platform Selection Framework: Match Workload to Strengths
- Choose AWS If: Need maximum service breadth and global presence. Require mature ecosystem with 200+ services. Custom AI silicon requirements (Trainium/Inferentia). Existing AWS infrastructure and expertise.
- Choose Azure If: Microsoft 365 or Active Directory integration needed. Hybrid cloud strategy with Azure Arc. Enterprise LLM access via Azure OpenAI (GPT-4o). Existing Microsoft enterprise agreements in place.
- Choose GCP If: Data analytics-first workloads with BigQuery. Kubernetes-native applications and microservices. Cost-sensitive AI training with TPU accelerators. Engineering team prefers clean APIs and simplicity.
- Multi-Cloud Strategy: Use cloud-agnostic formats: Apache Iceberg, Delta Lake. Avoid vendor lock-in through open standards. Implement abstraction layers for portability. Consider hybrid deployment for flexibility.
Slide 11: Data Lakes vs Data Warehouses: Architecture Strategy
Complementary solutions for modern data platforms
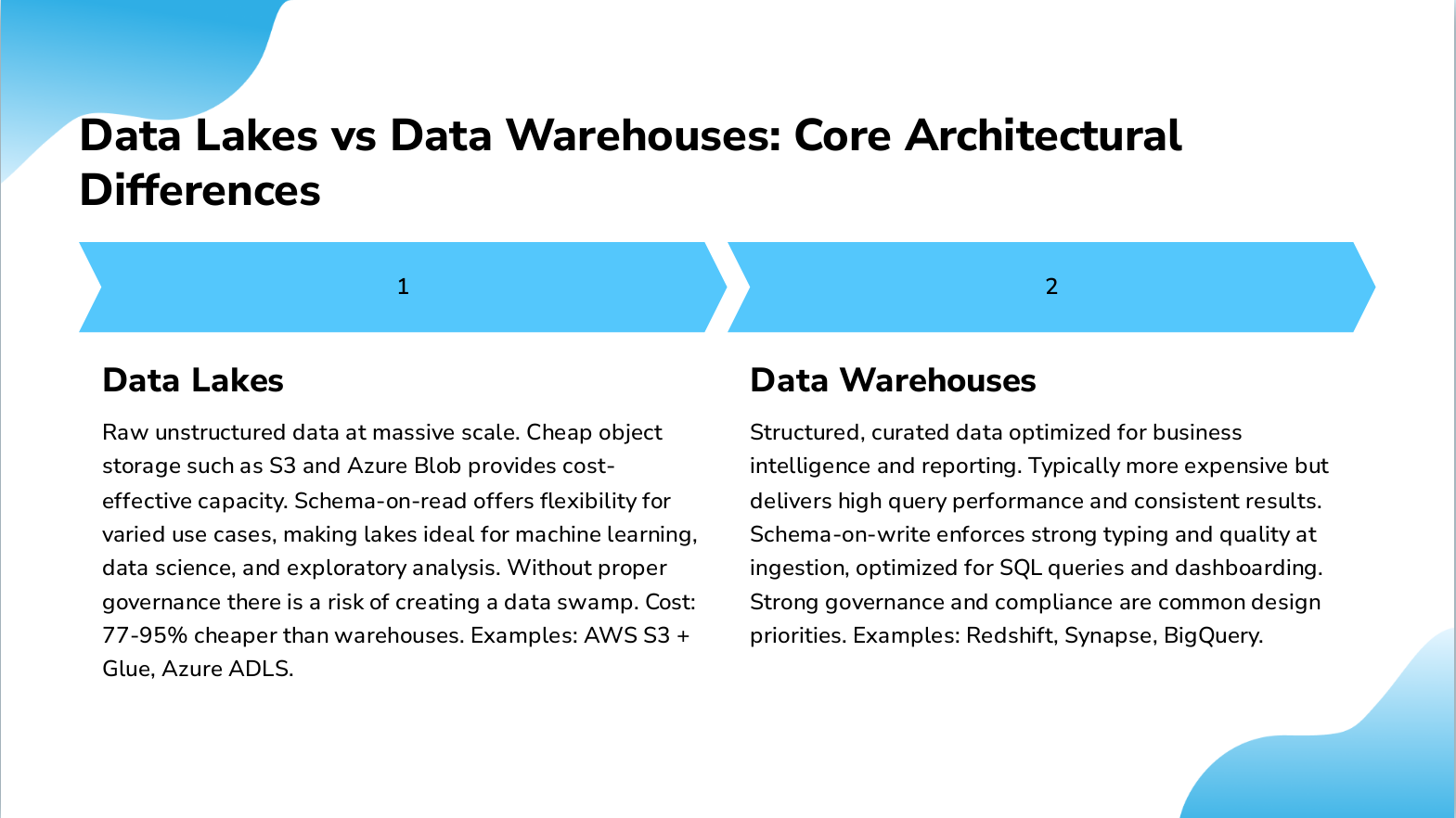
Slide 12: Data Lakes vs Data Warehouses: Core Architectural Differences
- Data Lakes: Raw unstructured data at massive scale. Cheap object storage such as S3 and Azure Blob provides cost-effective capacity. Schema-on-read offers flexibility for varied use cases, making lakes ideal for machine learning, data science, and exploratory analysis. Without proper governance there is a risk of creating a data swamp. Cost: 77-95% cheaper than warehouses. Examples: AWS S3 + Glue, Azure ADLS.
- Data Warehouses: Structured, curated data optimized for business intelligence and reporting. Typically more expensive but delivers high query performance and consistent results. Schema-on-write enforces strong typing and quality at ingestion, optimized for SQL queries and dashboarding. Strong governance and compliance are common design priorities. Examples: Redshift, Synapse, BigQuery.
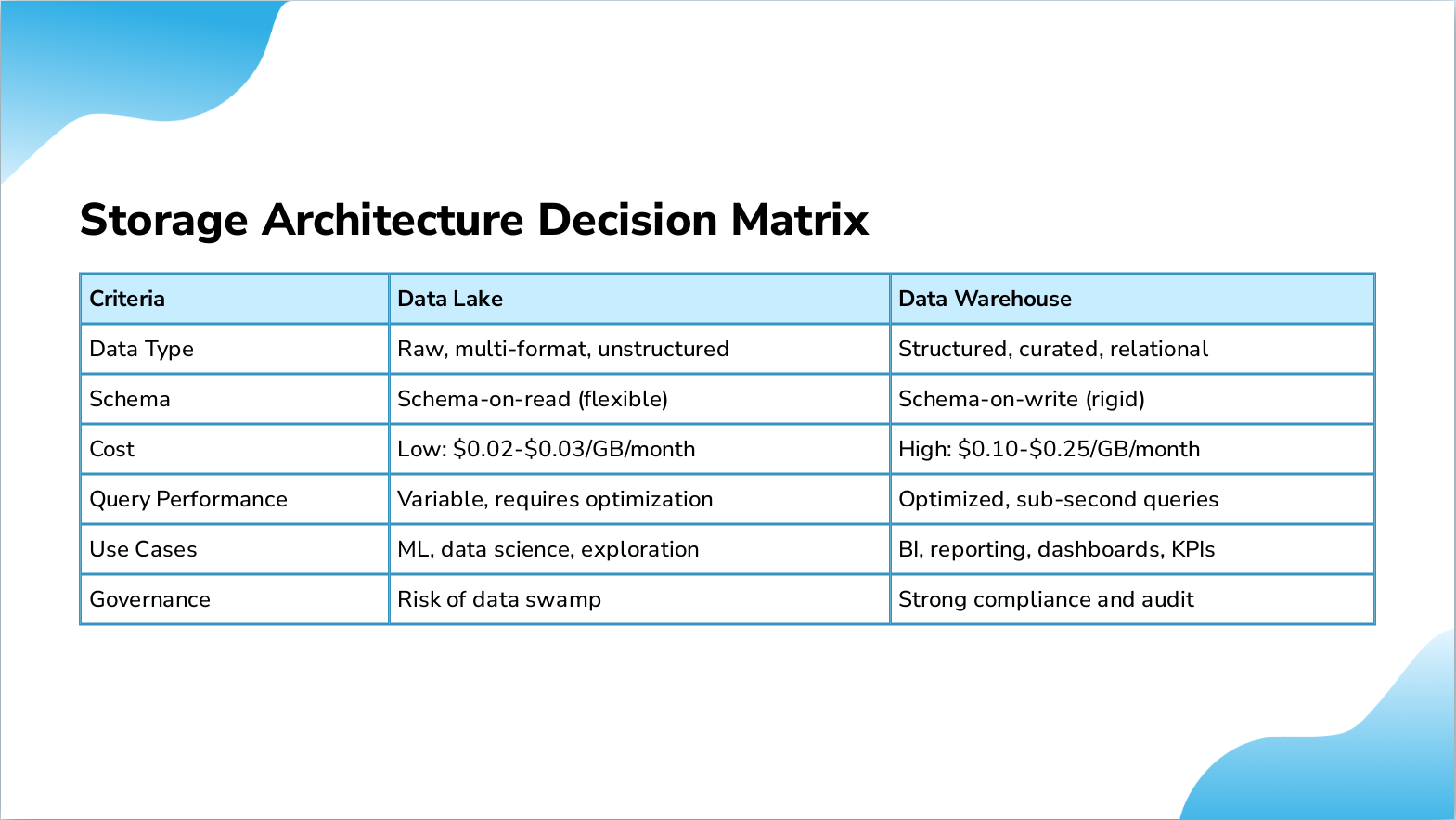
Slide 13: Storage Architecture Decision Matrix
- Criteria: Data Type, Data Lake: Raw, multi-format, unstructured, Data Warehouse: Structured, curated, relational
- Criteria: Schema, Data Lake: Schema-on-read (flexible), Data Warehouse: Schema-on-write (rigid)
- Criteria: Cost, Data Lake: Low: $0.02-$0.03/GB/month, Data Warehouse: High: $0.10-$0.25/GB/month
- Criteria: Query Performance, Data Lake: Variable, requires optimization, Data Warehouse: Optimized, sub-second queries
- Criteria: Use Cases, Data Lake: ML, data science, exploration, Data Warehouse: BI, reporting, dashboards, KPIs
- Criteria: Governance, Data Lake: Risk of data swamp, Data Warehouse: Strong compliance and audit
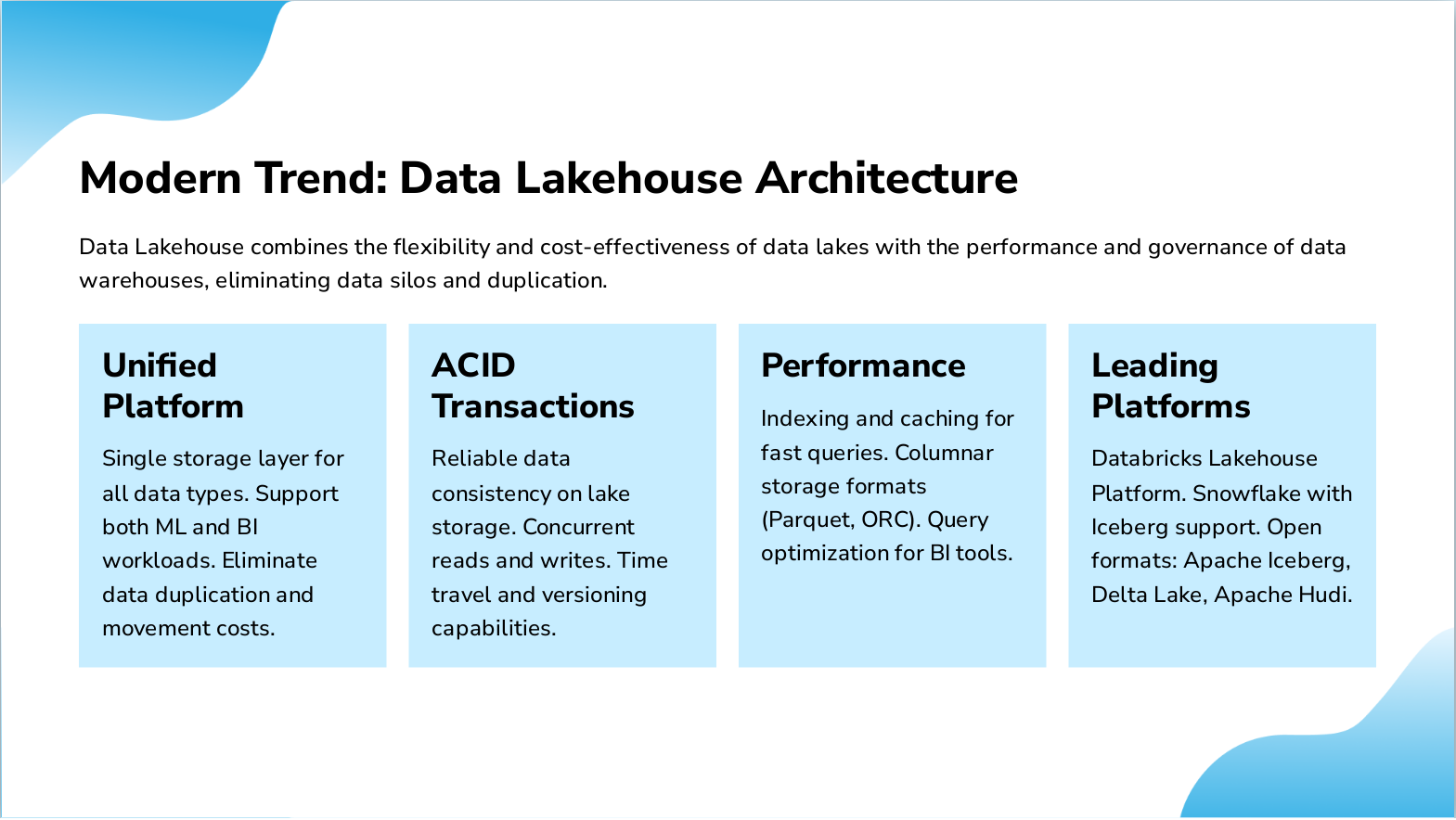
Slide 14: Modern Trend: Data Lakehouse Architecture
- Unified Platform: Single storage layer for all data types. Support both ML and BI workloads. Eliminate data duplication and movement costs.
- ACID Transactions: Reliable data consistency on lake storage. Concurrent reads and writes. Time travel and versioning capabilities.
- Performance: Indexing and caching for fast queries. Columnar storage formats (Parquet, ORC). Query optimization for BI tools.
- Leading Platforms: Databricks Lakehouse Platform. Snowflake with Iceberg support. Open formats: Apache Iceberg, Delta Lake, Apache Hudi.
Data Lakehouse combines the flexibility and cost-effectiveness of data lakes with the performance and governance of data warehouses, eliminating data silos and duplication.
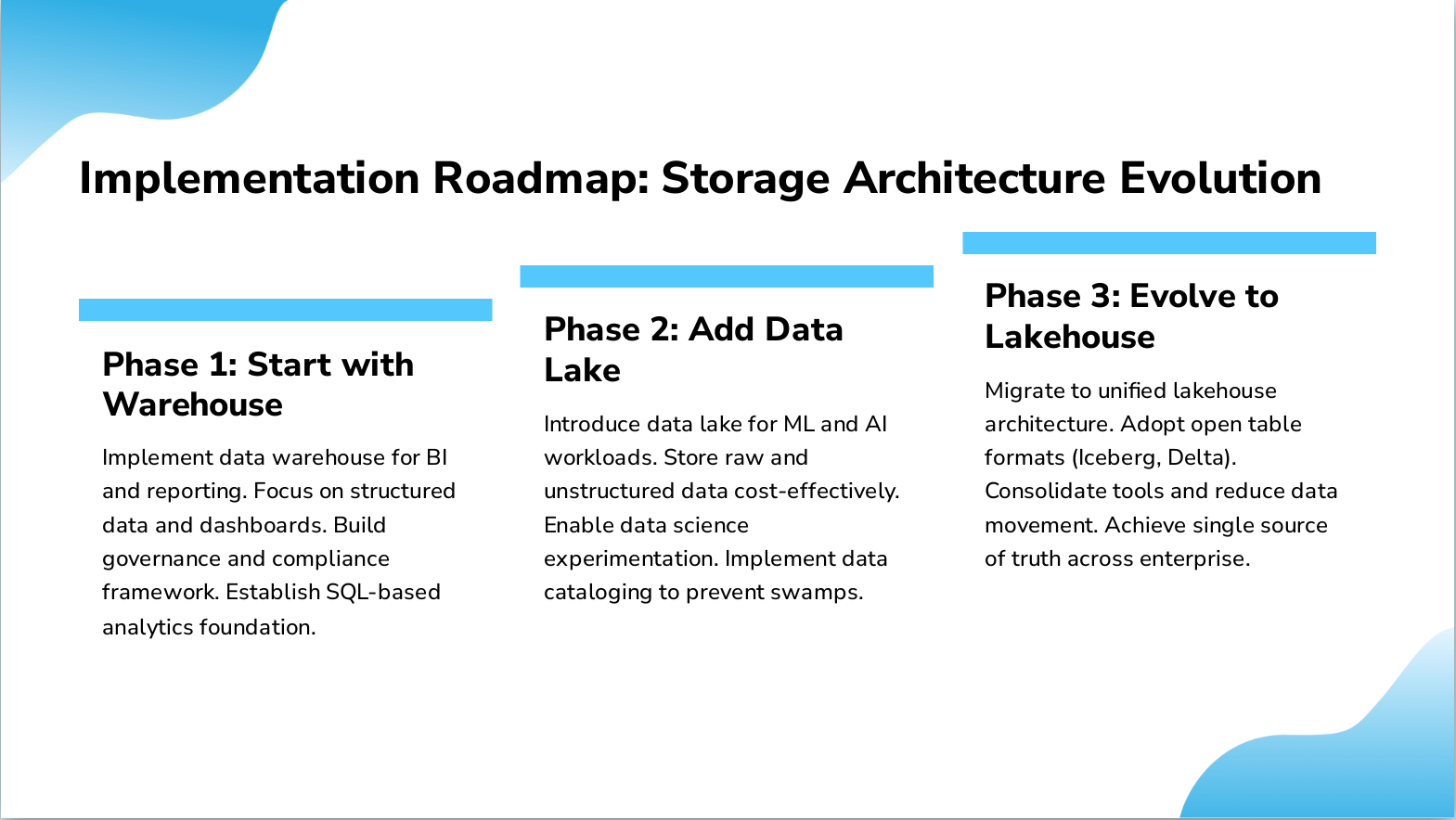
Slide 15: Implementation Roadmap: Storage Architecture Evolution
- Phase 1: Start with Warehouse: Implement data warehouse for BI and reporting. Focus on structured data and dashboards. Build governance and compliance framework. Establish SQL-based analytics foundation.
- Phase 2: Add Data Lake: Introduce data lake for ML and AI workloads. Store raw and unstructured data cost-effectively. Enable data science experimentation. Implement data cataloging to prevent swamps.
- Phase 3: Evolve to Lakehouse: Migrate to unified lakehouse architecture. Adopt open table formats (Iceberg, Delta). Consolidate tools and reduce data movement. Achieve single source of truth across enterprise.
Slide 16: Strategic Recommendations and Next Steps
- Immediate Actions: Define data classification strategy: hot, warm, cold tiers. Select primary cloud based on enterprise agreements and AI roadmap. Implement data lakehouse architecture to avoid silos. Establish data governance and security frameworks.
- Long-Term Strategy: Adopt open table formats for vendor independence (Apache Iceberg). Build edge computing layer for IoT and real-time processing. Invest in synthetic data and privacy-enhancing technologies. Plan for multi-cloud flexibility with abstraction layers.
- Success Metrics: Query latency under 3 seconds for BI workloads. Data pipeline reliability exceeding 99.9%. TCO reduction of 40-60% versus legacy on-premises. Time-to-insight reduced by 70% for data science teams.
Slide 17: Thank You
Thank You Questions and discussion welcome. Let's build scalable data architectures together.